In Serverless, Who Sets Up The Environment? What You Do & Don’t Have Access To

If you’re coming into the world of Serverless, especially if you’ve worked in a server-based world, you can end up confused about who exactly “sets up the environment in serverless”, and how the environment in Serverless works.
The whole Serverless ecosystem can be daunting—it definitely was for me when I started. At the end of this article, you’ll have more understanding about serverless, specifically how the environments are setup and hopefully you’ll have some “aha!” moments along the way!
In Serverless Who Sets Up The Environment?**In Serverless the environment is setup by the cloud provider. Many server-like access, such as process, log files, and SSH are unavailable to a Serverless user. However, different services and tools are available for serverless users to achieve similar behaviours to their server counterparts. ** To understand Serverless, you need to approach the idea with a “fresh mind”. If you have any existing notions about how applications / servers work, try to disregard those ideas for today. Let’s try and get your mind into the “serverless” way of doing things. Between server and serverless architectures, some things are the same, but many things are not.
Let’s take a look…Note: In this article we’ll talk about the topic in the context of AWS… but the ideas presented here are going to be very similar no matter which cloud provider you are using!
But First, What Is Serverless?
Before we start talking about how our serverless environment is setup, and what we do (and don’t) have access to, let’s quickly get on the same page about and define what we mean by “Serverless”.
I recently had a useful discussion on Twitter, about the different terms that come up in the Serverless world, and which ones are preferred so I’ll make sure throughout this article to be quite precise about the Serverless terms I use!
Useful clarification on terms surrounding Serverless 🙌🏼 Thanks [@NMoutschen](https://twitter.com/NMoutschen? ref_src=twsrc%5Etfw)! https://t.co/ZHol17kWtj — Lou 👨💻🏋️♂️🎸🚴🏻♂️🏍 (@loujaybee) [January 5, 2021](https://twitter.com/loujaybee/status/1346405152710926336? ref_src=twsrc%5Etfw)
Today, we’re talking specifically about: “serverless functions”.
Serverless functions are what most people mean when they use the word “serverless”. The term “serverless” is confusing, as it means any service (not just compute i. e functions) where you don’t worry about the underlying server. For example, databases can be serverless, DynamoDB is a good example.
But, let’s try not to get too far down the rabbit hole of the semantics of the word serverless! Today we’re talking about serverless functions. Simple. Except, what is a serverless function? And what defines a serverless function?

Serverless functions are a computing execution model, which allows a cloud platform user to run application code, elastically, on-demand, without giving consideration to factors such as: scaling, or server provisioning (i. e how many servers you need to run at any given time).
An important note for our to discussion today about serverless environments, is that—rather counter-intuitively—in serverless there is of course, a server! It’s just that you, the serverless functions user, don’t have access to it.
Serverless functions are best defined by it’s characteristics: you (the user) doesn’t worry about the server, your code scales relative to the demand automatically, and you don’t pay for any unused or idle resources.
Hopefully we’re now on the same page about “serverless”, so let’s turn our attention to today’s main topic: environments. Let’s start our conversation by looking at precisely the dividing line between what you’re responsible for, and your cloud provider is responsible for.
With Serverless: What’s Your Responsibility Vs The Cloud Providers?
In just a moment, I’ll walk you through what things you can and can’t access in a serverless environment. But let’s just take things a step back, and review a concept that’s important to our discussion: the shared responsibility model.
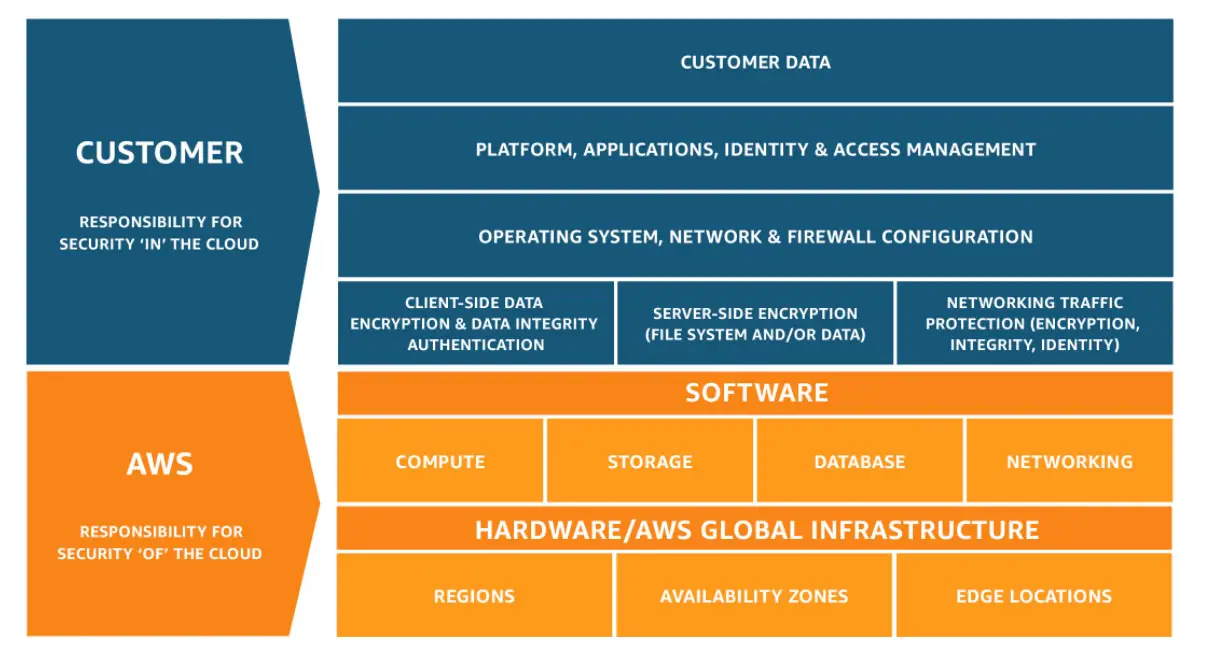
AWS Shared Responsibility Model
In cloud computing, because the physical server lives on a datacenter which is in the hands of the cloud provider, there need to be some “ground rules” about what the cloud provider is responsible for, and what you’re responsible for. A shared model is important for many reasons, especially legal ones!
The TL; DR is: Your cloud provider manages the physical servers, storage, cooling, physical security. In some cases the cloud provider worries about running correct versions of software on managed services. But, you as a user will manage things like your data, and the versions of software you run on non-managed services, etc.
The shared responsibility model is quite a big topic, so if you’re interested to get into the details, you can check out all the details over on the AWS shared responsibility model page.
Now let’s turn our attention back onto serverless functions, and talk specifically about the environment. Since we’ve learned that the cloud provider sets up the environment, let’s look at what you control vs. what the cloud provider controls when it comes to serverless functions.
Which Parts Of A Serverless Function Can You Access / Control?
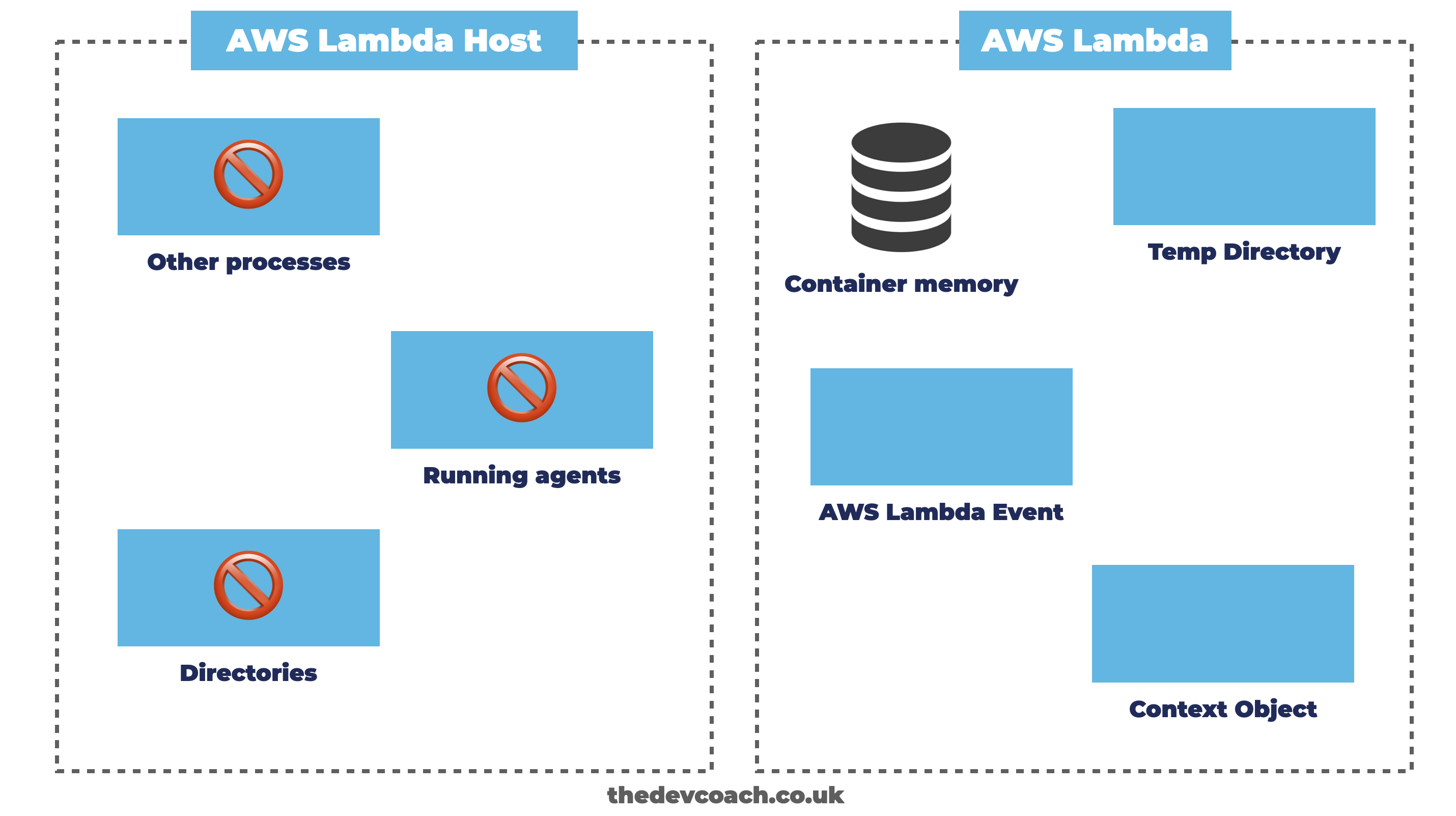
What can you access in AWS Lambda?
So, as we know now, even in a serverless world there is a server somewhere. Which raises the question: what parts of that server do you have access to?
Unfortunately, due to the amount of details about what you do and don’t have access to in serverless functions we can’t cover every small detail, so let’s focus our attention on the main points, which should be a good start.
What Information Does Your Serverless Function Receive?
With every invocation of your serverless function, there are things you’ll need to know: Who called the function? What are the arguments / options? And so on. In a server environment, you’d install a web server process, listen to an HTTP request, and handle incoming requests. With serverless functions, things are a little different.
So how do things get triggered in a serverless world? By events in the cloud eco-system. For example, you can trigger an AWS Lambda on a schedule, or through API Gateway, you can read the full list of AWS Lambda triggers here.
When these events / triggers happen, you’re given some data to help you understand and handle those requests / events. With AWS Lambda, you’re given two arguments for your function: anevent object, and acontext object.

Theevent object holds properties related to that specific invocation / event, usually details about a request, or an async event. Thecontext holds information about the AWS Lambda invocation / environment itself.
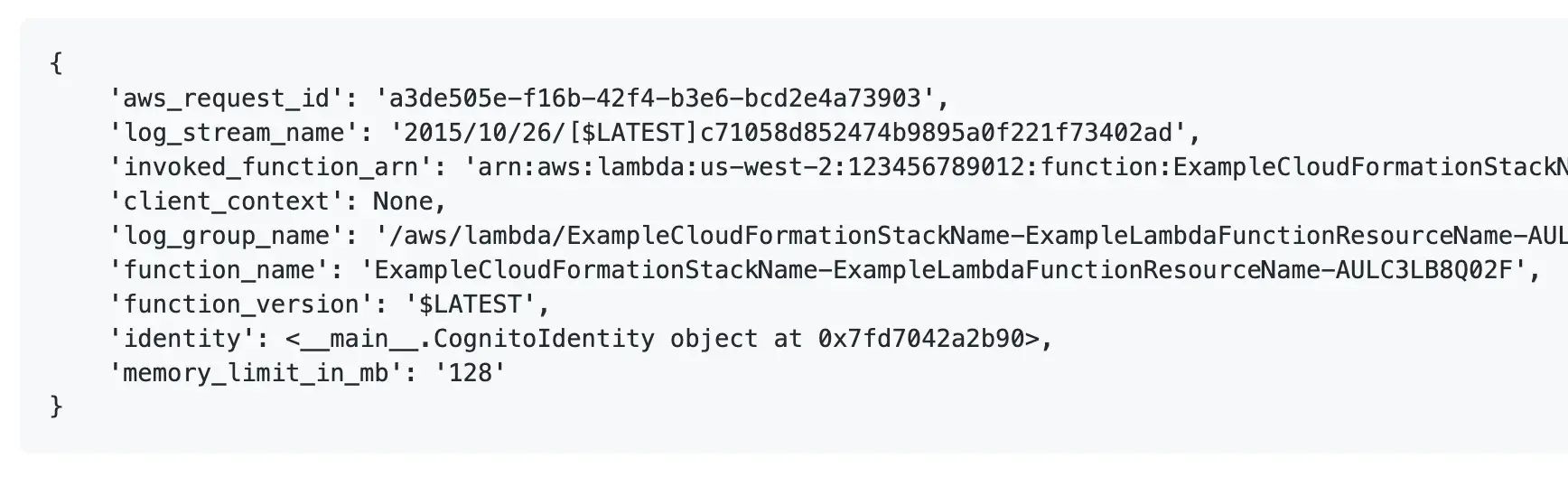
Hopefully it’s starting to become a little clearer now how the serverless model differs to a server one. If you want to create an HTTP API, for instance, rather than setting up a web server, you use one of the many web server cloud services like API Gateway, or an AWS ALB to route traffic to your AWS Lambda function.
There’s a lot more to this topic of context / events, but for now, let’s not get too buried in the specifics, and move onto another aspect of the environment you have access to, which is in-process memory.
How Do Serverless Functions Handle In-Process Memory?
Within AWS Lambda you can assign properties into memory, for temporary storage. This is particularly interesting to know, as this memory can be re-used between “execution environments” within AWS Lambda. But, what do I mean that memory is passed between execution environments?.
Let me explain: each time AWS Lambda scales your function for you, it needs to create a new execution environment (if it helps, think of it like another container, or mini-server). You can pass memory in between these execution environments, for as long as they live (which AWS decides). However, importantly you can’t pass memory between the execution environments.
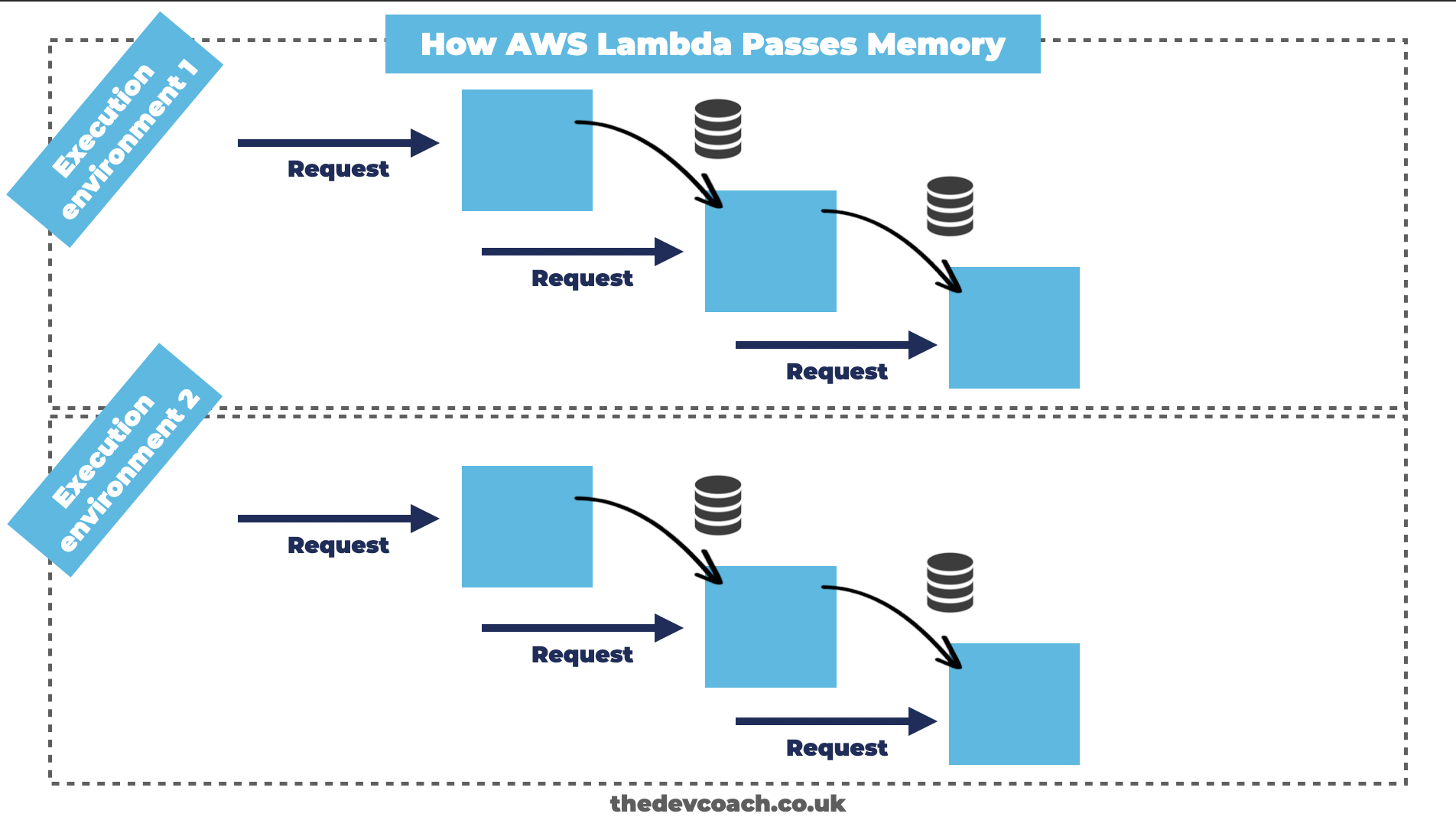
Since AWS control when to add new execution environments, you’re not guaranteed to be able to re-use the same memory on every invocation. Therefore you shouldn’t rely on values stored in memory, as you might in a large server environment. You can think of it like having two load-balanced servers, these servers can communicate, but they can’t directly share memory.
Can You Access Disk Space In Serverless?

It’s sometimes necessary to need to offload data to your disk space. For instance, to offload data into files as you performing some processing task. In the AWS Lambda implementation of serverless functions, you do have some disk space which you can use for storing temporary files.
Each AWS Lambda function has 500MB of non-persistent disk space in the/tmp directory. In this directory you can write any files that you need. Just remember that any files stored in temp aren’t shared with any other execution environments, and they won’t persist over time, after the execution environment is terminated.
If you need to store data longer-term, then you’ll want to integrate with an external, persistent service, like a database, or file system.
How Do You Allocate Resources To Serverless Functions?
Just like with a physical server, you can have a big server, a little server, two servers, a million servers, or just one server. The amount of servers, and the type / configuration will depend on your use case.
And when it comes to Serverless, you do also have some control over your power and configuration. But there are some nuances and limitations that you should be aware of.
For instance, in AWS Lambda, you can increase the amount of CPU, but this comes in lock-step with the amount of memory you allocate also. These two metrics are tied together for simplicity reasons.
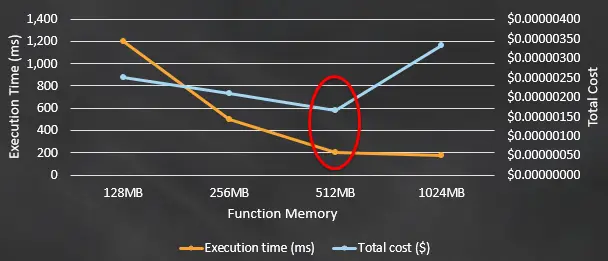
AWS Lambda Power Vs Cost Trade-Off (Source)
And, as you might expect, more power means more cost. However, counter-intuitively, more power might mean a faster function invocation, which could be cheaper because you don’t pay for idle resources!
You can use tools, such as the aws-lambda-power-tuning to help you figure out the best balance between cost, and power for your AWS Lambda functions. More power might mean better performance, but at a cost.
The AWS Lambda Power Tuning Library
Regardless, the allocated power of your serverless function is another thing in your “environment” which is within your control, in the Serverless world.
So we’ve covered a few things now that you have access to in your serverless environment: arguments, memory, and persistent disk space. There’s plenty more to dig into, we could spend all day!
But let’s keep our conversation moving forward by flipping our perspective, and take a look at some of the things which are not within our control in a serverless world.
Which Parts Of A Serverless Function Can You Not Access / Control?
So we’ve talked now about a handful of things that you do control, what about the things that are not in your control when you’re working with AWS Lambda?

Can You SSH into a Serverless Function?
Another concept for those working with regular hosts that they might be used to is SSH’ing. SSH is a form of remote access to the command-line. It’s typically used to perform server work, or upgrades. However, it should be used with caution, as modifying running servers in most cases is a bad practice.
Whilst researching this article, I did search around to see if anyone had hacked into AWS Lambda using SSH. It seems the answer is yes, but SSH isn’t an out-of-the-box feature, and there’s many reasons why SSH not only isn’t recommended, but it’s a great thing that SSH isn’t available to you.

In fact, the idea that you can’t SSH into AWS Lambda as a limitation, is really a forcing function to invest in other tools, such as monitoring, alerting and logging, which help you to “understand” your running software rather than SSH’ing in. I’ll never forget how sweaty my palms got SSH’ing into production, and tinkering with live code. Never again!
Can You Run An Agent on A Serverless Function?
One aspect to AWS Lambda that differs from a regular server, is the ability to configure different processes, such as agents on the host machine. Agents can be thought of like background processes, that are useful for doing tasks such as shipping logs, or metrics on a period basis.
With serverless functions, you can’t run an agent in the typical sense. An agent usually runs as a separate process on the host, for running tasks. But since serverless functions all run in different execution environments, you’d need a lot of agents.

However, just because AWS Lambda can’t run a typical server agent doesn’t mean this type of behaviour isn’t possible, because it is. These different pain points that make AWS Lambda different from the regular server environment is something that the AWS Lambda team are constantly fixing.
AWS recently released a feature, which can help you to implement agent-like behaviour, but from within doing things the AWS Lambda way, called “Lambda Extensions“. And there’s other features like this, where typical server behaviour has been carried over to the AWS Lambda world.
To learn more about Lambda Extensions, and what they mean for you, you might want to check out this article I wrote: Lambda Extensions: What Are They, And Should You Care?
How Do You View Log Files In A Serverless Function?
Similar to SSH’ing into a server, most software engineers with a background working with servers might be familiar with the workflow of dropping into a server, to parse and grep log files. But, as we mentioned, the idea of SSH is not built into AWS Lambda, or recommended.
So what’s the preferred, new approach? The approach with AWS Lambda, is to leverage an external service, such as CloudWatch. CloudWatch is the AWS managed monitoring service, and you can configure your AWS Lambda to ship logs to. But you don’t have to, as we mentioned before, there are many other options including third-party tools or self-hosting to choose from.
So, as we mentioned earlier on in the article, there’s lots more things that you could do in a server environment, that are not possible in (at least in the same way) with a serverless function. Hopefully going through those different areas has helped you to clear the fog of understanding about the difference between serverless and server environments.
Moving To The Serverless Mindset
As you can see, there’s lots to understand about the serverless “way of doing things”. To really wrap your head around how serverless works, you should try your best to let go of any preconceived notions from working with other patterns, to take in this new way of doing things in the cloud.
I really advise you to get hands on with serverless functions in order to understand some of these ideas, as some just won’t sink in until you’ve experienced running a function in a cloud environment. Experiment, explore, see what you can and can’t do, that’s the best way to learn.
To learn more about serverless, check out: Serverless: An Ultimate Guide, or if you’re really looking to get into cloud and serverless, check out: My (Highly!) Recommended Books / Courses To Learn Terraform.
I also write a newsletter every single month, which covers the main things which are going on in cloud engineering, you can find out more, see examples, past issues.
Speak soon cloud engineering friend!

Lou Bichard
Hey I'm Lou! I'm a Cloud Software Engineer. I created Open Up The Cloud to help people grow their careers in cloud. Find me on Twitter or LinkedIn.
See all posts →Latest posts by Lou Bichard (see all)
- 2024 Summary - A year of trips and professional work - January 9, 2025
- 2023 Summary - Data Driven Stories About The Cloud - December 31, 2023
- 2022 Summary - The Open Up The Cloud System - January 1, 2023