You’re Alerting Wrong - The Why & How Of Setting An AWS Lambda Alarm Using Error Rate Percentages.
When it comes to operating Lambda, we often want to configure alarms to alert us when things aren’t running smoothly. Naturally our first choice for Lambda alarms is CloudWatch, the default monitoring service that comes with AWS.
CloudWatch gives us some custom metrics out-of-the-box, such as: errors and invocation rates. But there are some problems we run into when setting up alarms based directly on these metrics. **By the end of this article you’ll understand why alarms based on default AWS Lambda Metrics can cause difficulty, how AWS Metric Math helps us to apply “context” in our alarms and make them more effective, and how to setup an alarm using metric math to calculate an error rate percentage. ## Note:**For today’s article, I’ll use Terraform for the examples. But, I’ll also explain what’s going on in each part, so you can translate back into whatever tool you are using. No need to worry if you don’t understand Terraform.
If you’re new to infrastructure as code, be sure to check out: Infrastructure As Code: An Ultimate Guide
Alerting: Why We Alert.
Alerting Threshold AWS
Okay, so to start our conversation, let’s take a whole step back, and consider why we setup alerts on software components in the first place.
Alarms exist to notify us when our system behaves in an unexpected way, which warrants manual intervention to correct. Intervention could be scaling up our services, restarting them or administrating an expired SSL certificate.
The important part to note here is the fact that alerts should “warrant manual intervention”. What do we mean by this exactly? It means that we should aim to only alert within our systems when our system cannot automatically recover and human intervention is absolutely necessary.
But why? Because if we alert too frequently, we end up suffering from what is known as: alerting fatigue. Alerting fatigue is when alerts are so frequent that they simply get ignored. When the time comes for a truly rapid response to an incident, response times will be sluggish sine the issue won’t be acted upon quick enough. So it’s important that we ensure that our alerts are meaningful.
When it comes to AWS Lambda and setting up alarms in CloudWatch, there are some pitfalls that you’ll want to avoid. Let me explain…
How AWS Metrics And Alarms Work
AWS Lambda Metrics
The way that alarms work in AWS (and many other monitoring tools) is via thresholds. You choose a metric (i. e number of errors), you choose a time period (i. e hourly) and finally you choose a threshold (i. e 5 errors). If the metric exceeds, or drops above or below that threshold, we can get alerted.
And, luckily, when it comes to AWS Lambda, we’re given some nice default metrics out-of-the-box which we can use as a basis for our alarms. These are: concurrent executions, duration, errors, throttles and number of invocations.
The skill of creating good alerts lies in finding the right balance of metrics, time periods, and thresholds. We need to choose appropriate metrics and thresholds given the context of our service. And at this point you might be wondering what I mean by “context”? So let me explain…
The Problem with AWS out-of-the-box Metrics
For instance, if one error out of five invocations occurs on a payment API, it could be worth investigating, but one error in a million serving a non-critical image might not be worth our attention. So when it comes to setting alarms we do want to incorporate these other factors, such as the number of invocations.
Which is why setting up alerts using only the default metrics can often be ineffective, as they don’t take into account wider context, such as the number of invocations. We might configure alerts that either fire too much, or not enough.
The solution? Take into account the context, such as the current traffic, and our tolerance for errors. But now you might be wondering: “How do we incorporate this context in a more practical sense?”
We can incorporate context using a feature in AWS CloudWatch called “metric math”. Metric math allows us to combine different metrics together to create new ones. Metric math is a simple concept, once you understand the principles.
Let’s now look at how metric math helps us achieve more effective alerting.
Configure An Error Rate CloudWatch Alarm
In 2018, AWS introduced a feature called “metric math”. Whilst metric math is conceptually simple, there are definitely a few fiddly bits that you’ll need to get your head around in order to fully understand how it works.
Let’s jump straight into the deep end and take a look at a full example of metric math in action…
When I first read this snippet I was like: “Woah! What’s going on here?”. To understand what’s going on, let’s start to break things down into three parts.
-
** The Alarm In Plain English**— We’ll start by understanding what this alarm is doing in plain english, when we strip away all the jargon.
-
** CloudWatch Alarm Values**— We’ll cover the CloudWatch alarm values, these are the values we must always set for CloudWatch alarms.
-
** Metric Math & Return Data**— Lastly we’ll cover how the metric math works, and how we assign our metric to our alarm.
Wowza, a lot to get through, let’s get to it.
1. Our Alarm Configuration In Plain English
Let’s start our breakdown by converting this alarm into plain english.
Our alarm is saying something like this…
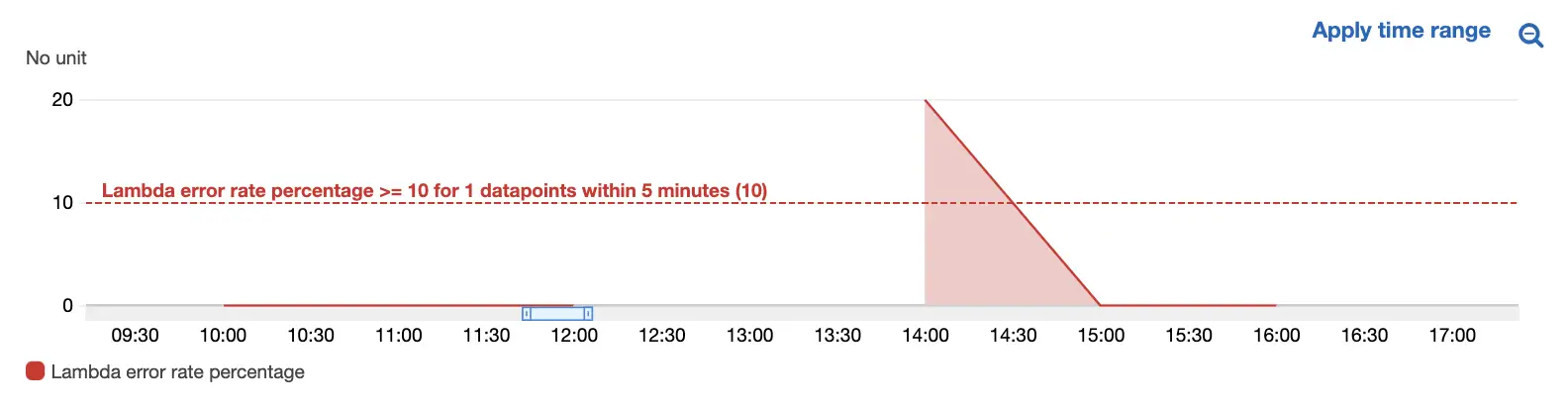
Trigger an alarm if the number of errors the lambda receives in any 15 minute window exceeds 5% of the total invocations. In other words, trigger an alarm if in a 15 minute window there is more than 1 erroneous invocation for every 20 successful ones.
And that’s all that’s going on, it’s just a case of understanding the syntax.
So let’s break down the syntax to start to understand it
2. CloudWatch Alarm Configuration
If you look back at the snippet, you’ll see there is a main block, associated with the alarm itself, and then a series of nested childrenmetric_query blocks. Let’s start with the first block, looking at the properties associated with it.
The first block is the CloudWatch alarm itself. Since AWS is quite modular by design, the alarm resource in AWS is merely a system for setting thresholds on metrics. CloudWatch alarms push actions to other services, typically SNS which then “do things” when the alarm is triggered.
This block is almost 90% of our alarm configuration, it’s just missing our metric (but that’s where things get interesting!)
So, what do the CloudWatch alarm values mean?
-
** Alarm Name / Description**— Add your own documentation to your alarm to more easily identify and understand it later.
-
** Comparison Operator**— Tells CloudWatch whether the alarm should trigger when a metric is greater than or less than the threshold.
-
** Evaluation Periods**— The number of periods in which the alarm is compared to the threshold.
-
** Data Points To Alarm**— The number of times the threshold needs to breach (in the evaluation periods) to be triggered.
-
** Alarm Actions**— What to do when the alarm is triggered.
-
** Threshold**— The value at which our alarm should be triggered.
These are the main ingredients of our alarm. It’s worth mentioning at this point that we could attach a basic metric to our alarm, such as the count of errors. This would then alert us if the count of errors exceeds 5 within a 15 minute window.
But, as we discussed before, by attaching a basic error rate like this, we’re likely to miss important scenarios, or we’re going to over-alert. Neither scenario is ideal. So, how do we add context and make our alarm more effective?
3. Metric Math Configuration
We add context to our alarm by configuring an advanced metric value. You can think of metric math as a small calculation that can be performed on top of your existing metrics at the point in which they are computed.
In our case, rather than taking errors to use with our alarm, we’re going to take the number of errors, and divide them by the number of invocations. In doing so we get a percentage of errors, which now takes into account invocations.
Now this means that our alarm will behave in the same way whether we get one request, or one million requests. And that’s important for our effective alerting.
Sounds good, but how does it work?
Metric math works by applying one or more queries and assigning the result to a variable, which is theid property. You gather up many of these “variables” as you need, before finally, returning an expression which utilises your variables, which can be seen in our final config block.
In our scenario, we first take the sum of errors in a 900 second period, which is 15 minutes, and assign the value toerrorCount. We then take the sum of our invocations in a 15 minute period, and assign the value to invocations.
Then finally we use the expression(errrCount / invocations) * 100 to create our new, metricerrorRate, which is the value of our expression that consists of two metrics. Can you see how that works?
Now our original CloudWatch alarm values, such as the threshold we originally set now apply to this metric. Notice how now the value is a percentage, not a static value? Our alarm is now configured so that it will alert us when our new errorRatepercentage exceeds 5%.
By using metric math, we’ve created a more powerful alarm then we could if we only used the simple out-of-the-box error metrics that we get in CloudWatch.
Effective Alerting, Completed.
By using the metric math feature in AWS we were able to write alarms that take into account the context of our service and are more powerful than the basic metrics alone. With metric math you can achieve some pretty neat things.
Hopefully that helped you better understand not only how alerts work in AWS, but how to write them effectively so that they’re actionable. Now hopefully you get more signal than noise which and end up responding to incidents faster!
Speak soon, Cloud Native friend!

Lou Bichard
Hey I'm Lou! I'm a Cloud Software Engineer. I created Open Up The Cloud to help people grow their careers in cloud. Find me on Twitter or LinkedIn.
See all posts →Latest posts by Lou Bichard (see all)
- 2024 Summary - A year of trips and professional work - January 9, 2025
- 2023 Summary - Data Driven Stories About The Cloud - December 31, 2023
- 2022 Summary - The Open Up The Cloud System - January 1, 2023