The 6 Concepts You Need To Know Before Trying Serverless

So you’ve been hearing a lot about Serverless? Maybe you’ve started to see some tell-tale signs your app could be broken down into microservices?
Serverless is a really awesome technology in the realms of Cloud Native Software Engineering. But, it can be a bit of a hard concept to get your ahead around if you’re not already familiar with many concepts of serverless.
Serverless computing as a principle is fairly easy to understand. But in order to effectively work with Serverless there are some other concepts that you should know about before you get going. And today we’re going to cover some of these unknown unknowns for working with serverless.
Today we’re going to discuss the following 6 concepts you need to know in order to get going with Serverless: Cloud Provider Knowledge, Microservices, Distributed Systems, Deployments, Monitoring & Observability and Infrastructure as Code. By the end of this article you should know the main concepts related to serverless and you should be confident in developing your own Serverless application!
Serverless: A Definition
Firstly, as always let’s start with a definition of Serverless:
Serverless is a cloud computing execution model that allows arbitrary code to be ran dynamically without the need to manage hosts and their additional complications like provisioning and scaling. Serverless concepts apply both to compute and also database workloads.
And with our definition out of the way let’s get to the concepts you should know before starting Serverless development.
1. Cloud Provider Knowledge
The first concept you need to know for Serverless development is: Cloud Providers! A cloud provider is the company that provides your Serverless functionality. A cloud provider could be AWS, GCP or another.
In order to deploy a serverless application you’ll need to know how to navigate your chosen cloud provider. You’ll likely need to understand how you use users, roles, etc to provide safe access. You might need to know how the cloud provider routes requests, possibly via an API gateway.
Alongside understand these service dependencies for your Serverless application, you’ll want to know the nuances and restrictions that are imposed by your cloud provider. Such as: how long your serverless application can run for at a time, how much memory is allocated to your Serverless function and how quickly your serverless function can start.
2. Microservices

Serverless, by it’s nature forces developers to adopt some form of a Microservice architecture. Therefore it is very beneficial to understand both the advantages, and limitations of a Microservice architecture.
Microservices are small, independently deployed services that implement small pieces of a businesses domain. The advantages a fine-grained approach includes (but isn’t limited to): they’re easier to maintain due to small business domains and easier to reason about and they can be deployed with different languages or technologies.
But Microservices aren’t straight forward. Microservices can be implemented incorrectly with the wrong boundaries, for instance. And incorrect boundaries can cause maintenance overheads. The implementation of Microservices can also introduce additional complexity and lead to repeated code between services.
Nonetheless, if you’re going to engage in Serverless, you should really start to understand the principles, advantages and disadvantages of the Microservices architectural pattern. ** Note:**I can highly recommend Building Microservices by Sam Newman as it covers Microservices in depth, so that means: testing, deployment, integration patterns etc. It’s really worth a read.
3. Distributed Systems
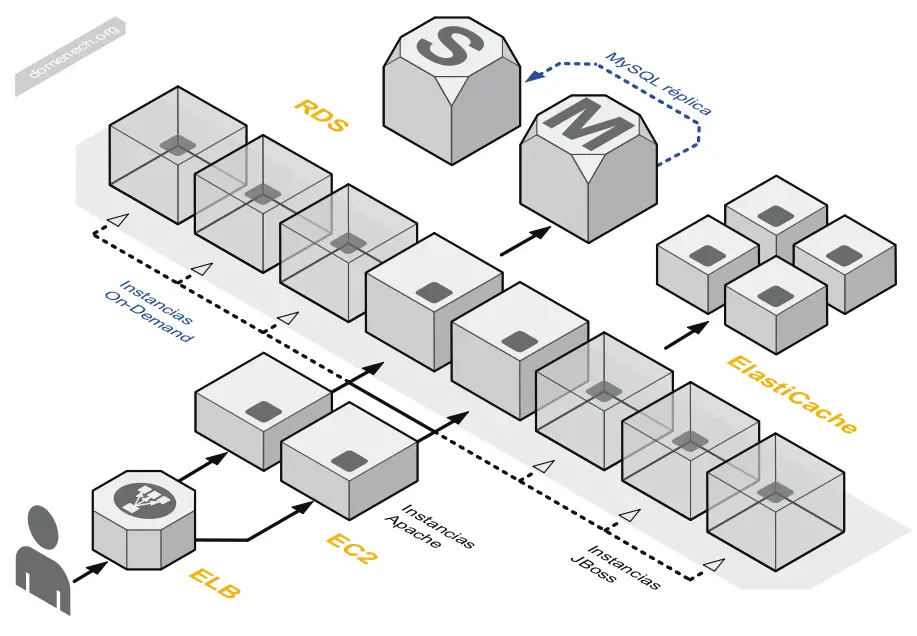
Similar to the concept of Microservices is the concept of a distributed system. As by nature, Serverless is distributed. Distributed systems are ones that need to communicate via a network, rather than with a single machine, for instance. In order for Serverless functions to communicate, they’ll need to send messages over the network, such as using HTTP or RPC or they’ll need to send or receive events.
Distributed systems are complex, since they require sophisticated monitoring, careful curation of API’s for system boundaries and they can be notoriously difficult to debug. But, as with Microservices distributed systems bring with them lots of benefits, so are worth exploring before getting into Serverless.
4. Pipelines: Continuous Integration & Continuous Delivery
Automation and deployment is essential for Serverless applications.
As Serverless functions are typically working as part of a Microservice architecture it is essential that the service contract doesn’t break and cause issues with downstream services.
We can ensure high quality services by building a rock-solid continuous integration / delivery pipeline. Tools such as Jenkins, Drone, etc allow engineers to test code quickly and frequently.
5. Monitoring and Observability

As we mentioned in distributed systems, Serverless systems require advanced monitoring. Often times a monolithic application has it’s monitoring setup from the beginning. However, having monitoring already setup leads engineers to become complacent in monitoring applications when they’re working with Serverless applications.
However, due to the added complexity from distributed systems it’s essential that developers can remotely debug services without requiring too many (or any!) additional changes to the service itself.
A good monitoring strategy reports to internal engineers before users do. We can implement observability in Serverless through 3rd party tools like DataDog or New Relic. Or we can leverage cloud platform tooling such as CloudWatch.
6. Infrastructure as Code
Infrastructure as Code (IaC) is the practice as writing your software as code. Infrastructure As Code helps with: flexible refactoring infrastructure, collaborating on infrastructure, restoring services in outages and much more.
If you’re going to build your Serverless application with something like Serverless Framework then the framework itself will handle a lot of the heavy lifting with your infrastructure.
But, if you choose to build Serverless applications without a framework you’re likely going to want to write your own Infrastructure as Code. So you’ll want to get familiar with tools like Terraform or CloudFormation.
It’s your turn to build on Serverless!
There are many other concepts you need to wrap your head around, but that’s the cost of being a cloud native software engineer!
And that’s it. These are the main concepts that you’ll need to understand in order to get going with Serverless. As always, the best way to get going with any technology is to try it out. So I’d suggest launching your own service.
I’ve also written about setting up a minimal Serverless application with Serverless framework before if you want to use that as a jumping off point!

Lou Bichard
Hey I'm Lou! I'm a Cloud Software Engineer. I created Open Up The Cloud to help people grow their careers in cloud. Find me on Twitter or LinkedIn.
See all posts →Latest posts by Lou Bichard (see all)
- 2024 Summary - A year of trips and professional work - January 9, 2025
- 2023 Summary - Data Driven Stories About The Cloud - December 31, 2023
- 2022 Summary - The Open Up The Cloud System - January 1, 2023