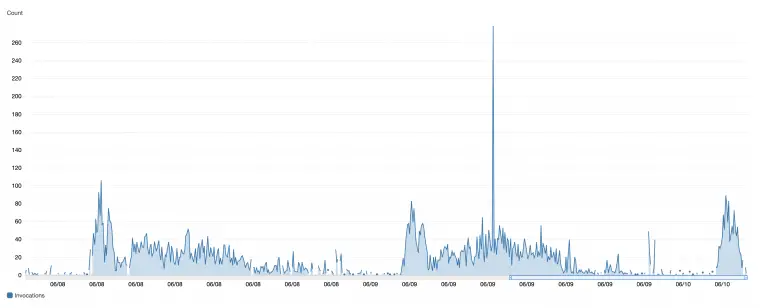
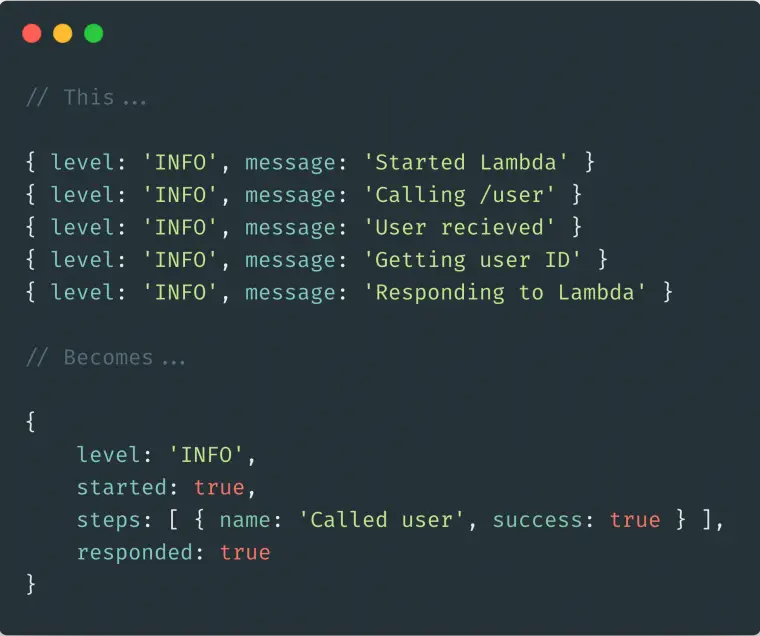
When it comes to operating Lambda, we often want to configure alarms to alert us when things aren’t running smoothly. Naturally our first choice for Lambda alarms is CloudWatch, the default monitoring service that comes with AWS.
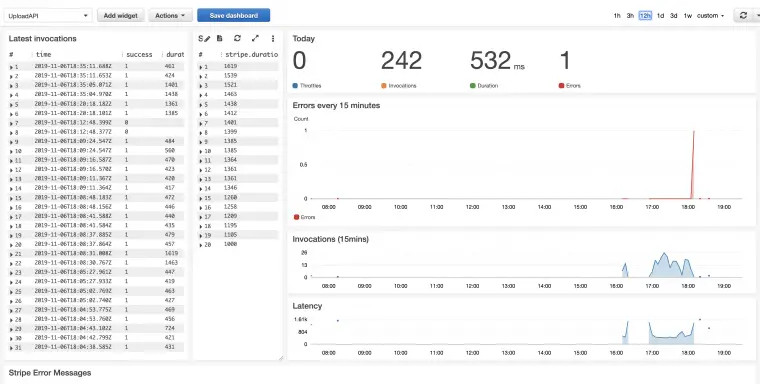
CloudWatch gives us some custom metrics out-of-the-box, such as: errors and invocation rates. But there are some problems we run into when setting up alarms based directly on these metrics.
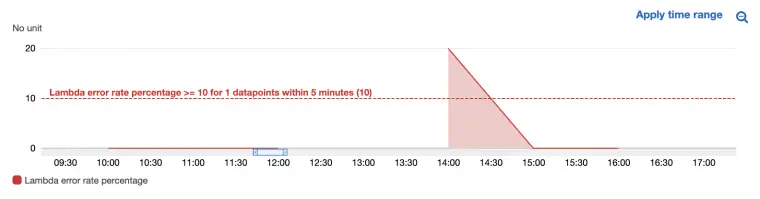
By the end of this article you’ll understand why alarms based on default AWS Lambda Metrics can cause difficulty, how AWS Metric Math helps us to apply “context” in our alarms and make them more effective, and how to setup an alarm using metric math to calculate an error rate percentage.